
Build the Workflow That Works for You and Fully Benefit from the Cloud Potential!
Usually, scientists have to do some manual steps to feed the results of a service into the next one - and then into the third, fourth and fifth. But now they can simplify their work. By composing the Helmholtz Cloud services to pipelines, the services interact. Processing, analysing and interpreting: adapted to the use case, the orchestrated services process the scientific data as an automatic sequence.
HIFIS is committed to prioritise the seamless linking of complementary services, with a particular focus on scientific workflow pipelines.

Key aspects of service orchestration scientific workflow pipelines include:
- Automation: Accelerating data processing and reducing errors.
- Modularity: Allowing researchers to organise complex analyses into manageable tasks.
- Reproducibility: Ensuring standardised, documented processes for result verification, including provenance information.
- Scalability: Adapting seamlessly to varying data volumes and research scales, e.g. with the potential for automatic parallelisation.
- Adaptability: Designed to evolve with changes, allowing researchers to update workflows as needed.
- Collaboration: Supporting collaborative research efforts by enabling multiple researchers to contribute to the pipeline, fostering interdisciplinary cooperation and knowledge exchange.

Set up of Minimal Service Orchestraion
By orchestrating these key components, as shown in the diagram, it is possible to build a minimal workflow pipeline, which is the basis for most of the more sophisticated scientific workflows that HIFIS would like to support. This Service Orchestration provides the following benefits:
Secure and controlled transfers
All transfers and orchestration steps take place within the Helmholtz infrastructure, ensuring secure authentication and authorisation methods.
Intermediate steps are finely controllable, allowing for privacy settings such as private, group-shared, or public, based on user preferences.
Flexible user access
Different steps in the pipeline can be configured for accessibility by various user groups, providing granular control over workflow access.
Persistent workflows
Workflows can persist for a defined timeframe, even when the original user(s) are offline.
Continuous updates triggered by incoming raw data ensure real-time results, enhancing workflow adaptability.
Dynamic computational resources
Easily scale compute power as needed at different points in time.
Seamlessly exchange or replace storage and introduce specific processing steps using different cloud services, demonstrating the modularity of the setup.
In summary, even a minimal Service Orchestration provides a secure, flexible, and modular framework that ensures controlled access, persistence, and adaptability to changing computational and storage requirements.
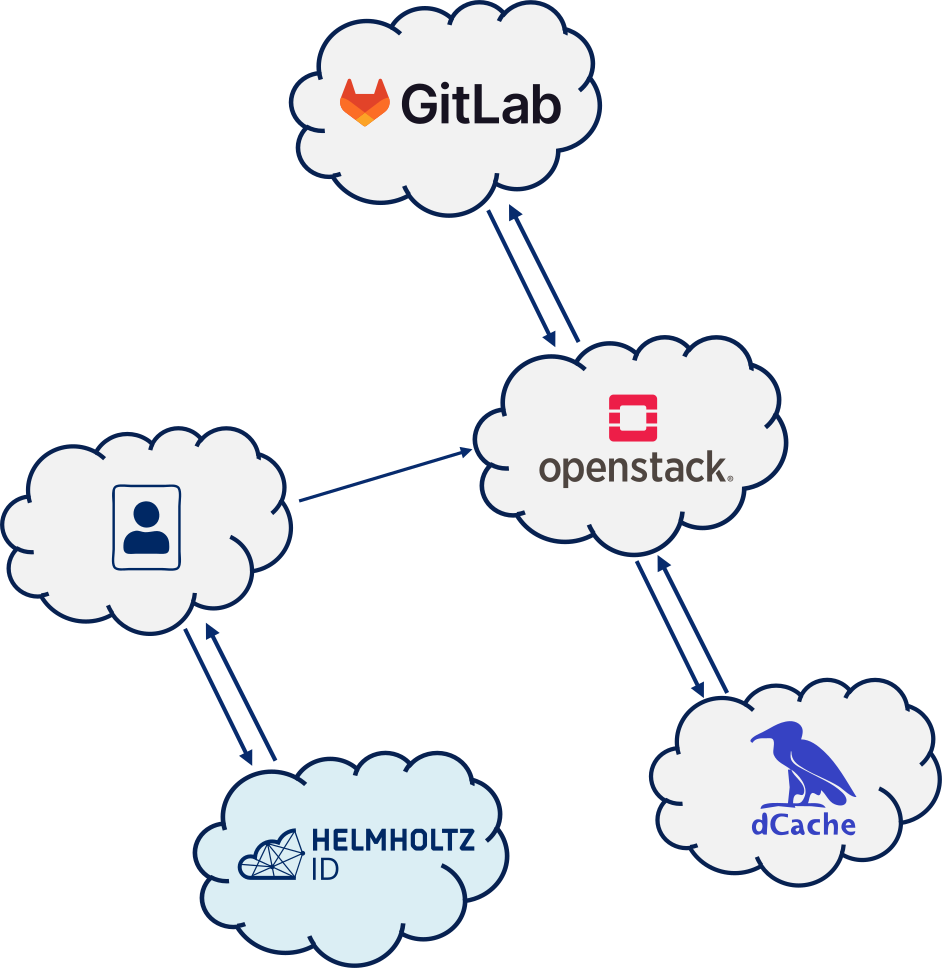
Scientific Workflows using Helmholtz Cloud Services
To address the many technical challenges behind Service Orchestration, HIFIS is consulting with various research groups to setup initial building blocks of scientific workflows. Starting from specific use cases, we want to improve the composability of our services and make future workflows easier to set up. So far, we have focused on the minimal Service Orchestration components to enable the following use cases:
Pilot Implementation in Helmholtz Imaging: Demonstrates the seamless interconnection of HIFIS Cloud services across five Helmholtz centres, showcasing modularity and utilising data from a research paper on intracellular organelles and insulin secretion.
NEST Desktop use case: A user-friendly, web-based GUI for the NEST Simulator, facilitating the creation and simulation of spiking neuronal network models without the need for programming skills. Powered by the HIFIS Cloud Service "Rancher" and Helmholtz ID.
Technical Basis to Connect Services
However, the composability of services for scientific Service Orchestration requires some key components:
- Authentication and Authorisation Infrastructure (AAI): Enabling members of different institutions to access protected information distributed on various web servers.
- Versioning and Revision Control: Incorporating mechanisms to track changes for transparency and reproducibility.
- Build Automation: The process of automating tasks involved in compiling source code into executable programs or libraries, including testing code for faster development cycles and more reliable releases.
- Data Storage and Ingestion: Acquiring relevant data from various sources.
- Compute Resources: Managing the computational aspects, covering data processing, analysis, error handling, logging, data visualisation, and result output generation.
Outlook for the Orchestration of Helmholtz Cloud Services
-
As we continue to develop use cases with several research groups, we will expand both our orchestration offering and the composability of existing cloud services. We believe that there is significant added value to be gained from service orchestration, and this is a point we have also heard from our users. As already mentioned in 2023, we will therefore continue to focus on this task in 2024 and 2025 to improve our orchestration capabilities.
-
We will continue to develop the minimal Service Orchestration with the aim of creating a tutorial for researchers to initiate their own workflows from this base.
-
We will work to document the lessons learned and best practices on service orchestration in general, as our experience grows.
-
In collaboration with HMC, we plan to investigate generating standard and appropriate provenance information metadata for data that has been processed using one of our workflow pipelines.
Queries, Comments and Ideas
If you have a use case or ideas about on our (scientific) Service Orchestration offer, please contact our Service Orchestration team.